こんにちは、佐々木です。
1週間前から、SNSのタイムラインでAmazonプライムデーの商品が溢れてきて、そわそわしてる人も多いのではないでしょうか。私もそうです。
せっかくの機会なので、ガジェット好きの一人としてAmazonプライムデーのお勧めの品を紹介しようと思います。奇をてらったものを紹介するつもりもないので、どっかで見た奴やんと思った人は、その感想とともにSNSで呟いてくださいw
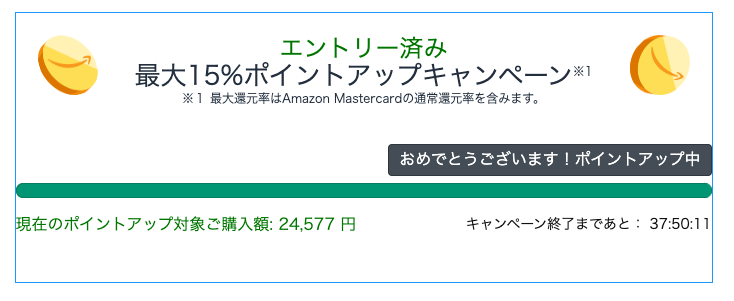
最初に設定するもの(ポイントアップキャンペーン最大15%還元)
プライムデーで、最初にする設定としてはポイントアップキャンペーンへの申し込みです。キャンペーンに応募するだけで、2024年6月25日(火) 14:00 ~ 2024年7月17日(水) 23:59の間のポイントアップがされます。
もう既に買っちゃったという人もご安心ください。後からでも有効な部分もあるようです。
Amazon Echo
プライムデーで買うものと言ったら、Amazon Echo
50%近い値引き率で販売されています。実際のところ、私はEchoをプライムデー以外で買ったことはないです。(初代をアメリカで買った以外には)
Echoもいろいろな種類がありますが、個人的にはディスプレイ付きがお勧めです。スマートディスプレイというタイプになりますが、お勧めは次の2種類です
Echo Spot(2024年発売)
今回のプライムデーで新発売したEcho Spotの最新版です。
画面が半分になって、スピーカー部分が拡張されています。音質アップを狙った製品でしょう。
定価11,480円のところ、48%オフで5,980円
 - スマートアラームクロック with Alexa、鮮やかなサウンド | グレーシャーホワイト")
Echo Show 5 (エコーショー5) 第3世代
ディスプレイが大きなタイプがEcho Show
その中のエントリーモデル(廉価版)が、Echo Show 5です。
定価12,980円のところ、46%オフで6,980円
 第3世代 - スマートディスプレイ with Alexa、2メガピクセルカメラ付き、チャコール")
ディスプレイが大きく使いやすいです。今回私は、キッチン用と子供の部屋用に2台買いました
Amazonプライムデーの先行販売で買ったAlexaさん到着
— Takuro SASAKI (@dkfj) 2024年7月15日
台所と子どもの部屋に置く予定https://t.co/cclR0NmmBy#Amazonプライデー pic.twitter.com/whe0KpIqtY
スマホのワイヤレス充電器(Qi認証)
今までスルーし続けてきたスマホのワイヤレス充電器
今回、遂に買いました。Qi認証の前提のもと、何かあったらすぐ交換してくれるAnkerの中から探しました。
立てかけて使えるようにスタンドタイプを選びました。色は黒と白があって、何故か黒の方が定価が安く、プライムデーの対象商品
定価2,499円のところ、20%オフで1,990円
※白だと2,890円
")
庶民のAirTag Ankerの紛失防止トラッカー
海外出張をする機会が、最近再び増えてきました。
コロナ禍前に比べて、空港のオペレーションも低下しているのか、ロストバゲージの頻度が上がっているようです。
対策として、庶民のAirTagこと、Anker Eufy Security SmartTrackのキーホルダータイプを購入して家の鍵につけるようようにしました。(普段は鍵につけておいて、海外出張時にスーツケースにつける運用)
これがなかなか良いので、財布用にカードタイプのものを今回購入しています。
定価3,999円のところ、33%オフで2,690円
 Security SmartTrack Card (紛失防止トラッカー) 【 Appleの「探す」に対応 (iOS端末のみ) / なくしものが、無くなる/紛失防止タグ/探し物/スマホが見つかる/置き忘れ防止/スマホ鳴らす】")
大容量モバイルバッテリー
既に購入しているので、今回は買っていませんが、プライムデーでのお勧めの1つは大容量モバイルバッテリー。
ちょっとした外出時ではなく、出張やイベントでガツンと外出するときに、PC含めて充電できるのでお役立ちです。
何が良いかというと、結局Anker製品。流派としては、充電器一体型のAnker 733と独立型のものがあります。
私は取り回しがしやすい、独立型を選んでいます。充電状況や残容量がディスプレイに表示されるのが、思った以上に便利です
定価24,990円のところ、24%オフで18,990 円
 (モバイルバッテリー 27650mAh 合計最大250W出力 大容量 LEDディスプレイ搭載)【USB Power Delivery対応/PPS規格対応/PSE技術基準適合/USB-C入力対応】iPhone MacBook Galaxy Android スマートフォン ノートPC 各種 その他機器対応 (ブラック)")
これと、薄型の充電器をセットで持ち歩いています。薄型のものは新しいモデルは最近でておりません。
自分が使っているのは、4年前のモデル
 PSE技術基準適合/PowerIQ 3.0搭載 / Power Delivery 対応/折りたたみ式プラグ iPhone 14 / 13 / 12、MacBook Air、その他USB-C機器対応 (ブラック)")
出張時の持ち歩きセットについては、このあたりに書いています
blog.takuros.net
電動式昇降デスク FLEXISPOT E7B
これも過去にかったので、今回は購入していません。
FLEXISPOTの足だけモデル。天板は、ホームセンターで買うと随分安くつくれます。
E7モデルを推す理由としては、足が3段階に昇降するところ。かなり低くまで設定できるので、それが便利です。
定価57,000円のところ、30%オフで39,900 円

導入の顛末はこちらです
blog.takuros.net
アプリ切り替え Elgato Stream Deck MK.2
今回紹介している中で唯一まだ買っていないのが、ストリームデック
これアプリ切り替えのスイッチみたいなものですが、便利そうで欲しい。けど、ちょっと用途に比べて高いような気がする。
ということで、もう少し調べて買うかもですという商品
定価22,980円のところ、26%オフで16,960 円

まとめ
こうやって値段をまとめてみると、末尾が990円とかギリギリ桁を一つ下げる割引率が設定されていますね。
Amazonプライムデーの担当者と、メーカーのギリギリの交渉が垣間見れるようで、少しおもしろいです。
ということで、物欲まみれのブログエントリーでした。
")
")



 (24000mAh / 大容量モバイルバッテリー) 【USB PD 3.1 対応/PSE技術基準適合/USB-C入力対応 / 140W出力】MacBook PD対応Windows PC iPad Pro iPhone Galaxy Android スマートフォン ノートPC 各種 その他機器対応")


 デザイン/PSE認証済/PowerIQ 3.0搭載 / Power Delivery 対応/折りたたみ式プラグ iPhone 14 / 13 / 12、MacBook Air、その他USB-C機器対応 (ブラック)")
 0.15m USB2.0認証品 3A出力 最大480Mbps ブラック U2C-MBFCM01NBK")

ブラック")
