日本のAWSのAPN Ambassadorが集まって作り上げるJapan APN Ambassador Advent Calendar 2020の初日です。佐々木の方からは、最近の関心事項であるマルチアカウント管理の中から、認証(ログイン)の一元化の設計について考えてみましょう。
マルチアカウント管理における認証(ログイン)の一元化の必要性
AWSを本格的に使い始めるとすぐに直面するのが、利用するAWSアカウントの増大です。AWSのお勧めのプラクティスの一つとして、用途ごとにAWSアカウントを使い分けてリスクを下げるというのがあります。本番環境と開発環境が同居しているより、分離した上で使えるユーザーを役割ごとに限定した方がリスクを下げることができますよね。一方で、プロジェクトごと・環境ごとにAWSアカウントを分離していくとすぐに10や20のアカウントになってしまいます。その時に第一の課題となるのが、IAMユーザーの問題です。

AWSアカウントごとにIAMユーザーを作っていくと、ユーザーごとにIAMユーザーのIDとパスワードが10個も20個もできてきます。さらにAWSに携わる人が数十人いたら、数百のオーダーのID管理が必要となります。これを個々のユーザー任せで適切に管理することができるでしょうか?なかなか難しいのが現状で、放っておくと全部同じID・パスワードで運用されるといったことも発生しうるでしょう。そこで、必要になってくるのが認証(ログイン)の一元管理です。
認証の一元化のデザインパターン
認証の一元管理にも、AWSの機能のみで管理するパターンやサードパーティのツールを駆使するパターンなど幾つかあります。代表的なパターンを幾つかみていきましょう。
踏み台AWSアカウントパターン
一番お手軽なのが踏み台AWSアカウントパターンです。踏み台となるAWSアカウントのみにIAMユーザーを発行し、後はクロスアカウントのスイッチロールでスイッチしていくパターンです。
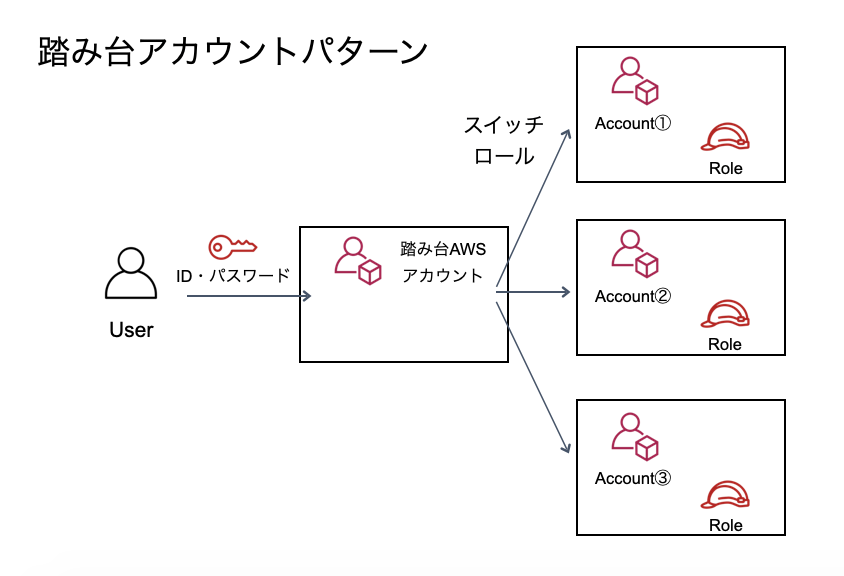
このパターンは、踏み台となる一つのAWSアカウントのみにIAMユーザーを発行し、他のAWSアカウントにはIAMロールのみ発行します。踏み台にログイン後にスイッチロールを利用してそれぞれのAWSアカウントを利用します。スイッチされる側のIAMロールで、スイッチできるIAMユーザーを制限できるので各アカウント側で権限の制御ができるのがポイントです。また、このパターンだとAWS Organizationsで管理外のものでも簡単に利用できるというメリットもあります。ただし、スイッチ先の各アカウントでCLIを利用したい場合は、一工夫が必要となります。
なお、このパターン名は、私が勝手に名付けているだけです。
サードパーティのIdP(Identity Provider)を利用するパターン
次に紹介するパターンは、ある意味王道であるサードパーティのIdP(Identity Provider)を利用するパターンです。IdPは認証部分を専用のシステムに委託し、認証した結果を受け取ってAWSアカウントの利用を許可するパターンです。IdPを利用するとAWS側でID/パスワードの管理が不要になります。代表的なIdPとしては、Microsoft Active Directory(AD)やGoogle Workspace(旧G Suite),Okta,OneLoginなどがあります。

IdPを利用するパターンも、AWS部分はIAMロールを使います。そのため、踏み台AWSアカウントパターンと構成的には大きく違わないように見えます。しかし、ポイントはAWSアカウント内に一切IDとパスワードを持つ必要がない点にあります。AWSを使うような組織は、AWS以外にも様々なシステムを利用し、ID/パスワードを管理する必要があります。そこにAWSのID管理を統合できるのは大きなメリットです。一方で、踏み台AWSアカウントパターン同様にCLIを利用したい場合は一工夫が必要です。
AWS SSOを利用するパターン
3つ目のパターンとしては、AWS SSO(AWS Single Sign-On)です。AWS SSOは、その名の通りマルチアカウントでのAWS運用を想定したサービスです。AWS SSO用のログイン画面があり、ログイン後に自身が利用できるAWSアカウントを選択できるようになっています。
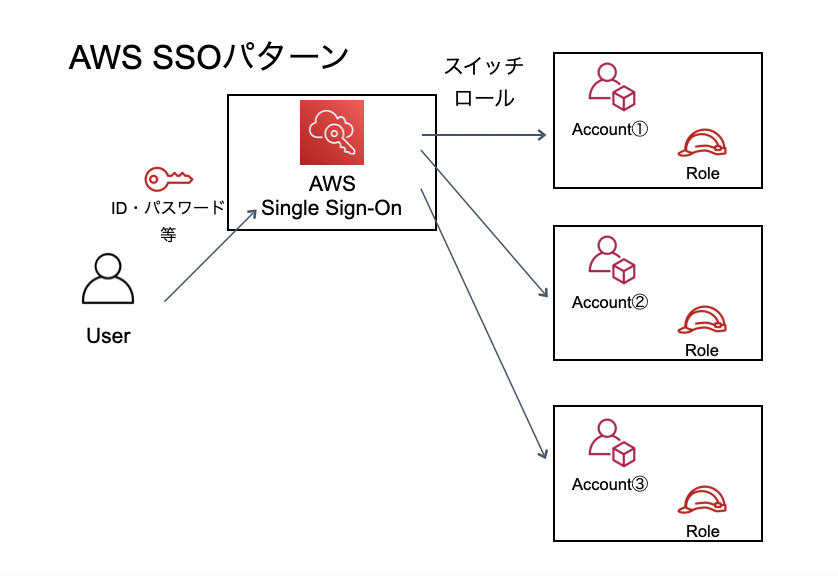
構成的には、IdPパターンと大きく変わりませんが、メリットは幾つかあります。そのうちの1つが、SSOから利用しているユーザーもCLI(v2)が使えることです。もう一つは、アクセス権限セットという機能を使って、複数アカウントのアクセス権限を一元管理できることです。ただし、SSOの利用はAWS Organizationsが前提となります。それにしても、これいいじゃんってなりますよね。ただ、お勧めの使い方としては別パターンがあるので、SSOのアクセス権限セットを説明の後で紹介したいと思います。
AWS SSOのアクセス権限セット
先程紹介したどのパターンでも、IAMロールが肝になっているのが解るでしょうか?認証の一元化はできても、どの機能が使えるかという認可の部分については各アカウントに設定されたIAMロールに依存することになります。そのため、個々のアカウントにIAMロールを設定していくという作業が必要になります。AWS OrganizationsとCloudFormation StackSetsを使えばこの辺りの作業もだいぶ楽にはなりますが、一元管理とは少し遠い世界です。
そこで登場するのがAWS SSOのアクセス権限セットです。アクセス権限セットはユーザーごとのアクセス権限を一元管理する仕組みです。SSOを設定するOrganizationsの管理アカウント(旧マスターアカウント)で定義します。アクセス権限セットと呼ばれるポリシーを作成し、ユーザーがどの権限を利用できるかを紐付けます。管理者の操作としてはこれだけなのですが、アクセス権限セットの良いところは、裏で対象のAWSアカウントの方に、アクセス権限セットと対応するIAMロールを作っているということです。まさしく一元管理!!
お勧めのデザインパターン IdP + AWS SSO
アクセス権限セットとCLI対応の2点でAWS SSOがお勧めです。一方で、いろいろな現場でSSOを紹介しても、やっぱり既存のIdPを使いたいというケースが多いです。やっぱりIDの二重管理は嫌ですもんね。そんな時にお勧めがIdP + AWS SSOというパターンです

構成としては、ユーザーはIdPでまず認証します。認証後にAWS SSOのポータル画面に移動します。そして、任意のAWSアカウントに移動するというパターンです。画面遷移が一つ増えるという手間が増えますが、このパターンには大きなメリットがあります
- ID管理をAWS以外も含めて一元化できる
- 認証(IdP)と認可(アクセス権限)を明示的に分離できる
- AWS SSOの機能が100%利用できる
- 今後AWS SSOの機能が増えてもグヌヌとならない
まとめ
AWSのマルチアカウント管理については、踏み台AWSアカウントあたりから始める人が多いのではと思います。コストも掛からないので、それで充分な場合も多いです。一方で大規模になると辛くなるということもあります。そんな際の参考になれればなと思います。
じつはこの辺の話をAWSの薄い本Ⅲとしてまとめようと思いつつ、はや半年が過ぎました。1行もかけていません。年内に執筆在庫を一層して、年初あたりから取りかかれればと思っておりますので、生暖かい目で見守ってください。また、AWS SSOを使う上では、Organizationsが必須となります。請求代行使っててOrganizations使えないよという方は、Organizations対応の支払い代行とかしているところを検討するといいんじゃないかなと思います。(ステマ)
今回は論理設計の話が中心だったので、もう少し具体的な話を今後紹介していきます。乞うご期待!!













